The Unreasonable Effectiveness of Ensembling
A diverse and incentivized crowd will find truth that no individual can
There's something magical about ensembling. I still remember the first time I averaged together a handful of mediocre models and watched the combined prediction outperform nearly every individual model on the board. A few were noisy and more than a few were overfit, but the very naive average of this dumb, unweighted, equal-weight average, kept working extremely well. This was one of those times that the ratio of how simple your approach is to the quality of the results you get out of it blows past your expectations.
With more experience I've only become more convinced. At CrowdCent, we've built an entire system around this principle where independent ideas and ML models from different people, different programming languages, different thoughts about what matters, are all aggregated into a single meta-model that guides real capital allocation. This post is about sharing why that works so unreasonably well, and walking through some experiments that make it concrete.
Vox Populi
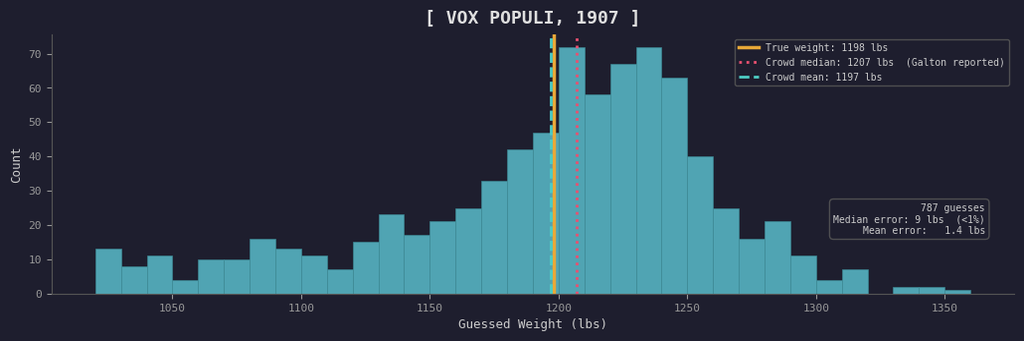
Forgive the trope, but we'll begin our story of ensembling in 1907, at a livestock fair in Plymouth, England. Francis Galton, a polymath and statistician, attended the fair and observed a weight-judging competition. A mix of around 800 farmers, butchers, clerks, and random passersby paid sixpence each to guess the dressed weight of an ox. Their individual guesses ranged from absurdly low to absurdly high, and most people were very wrong.
But when Galton tabulated the results, the median of the guesses came to 1,207 pounds. The actual weight of the ox was 1,198 pounds. The mean was even closer, off by only a single pound.
787 guesses, most of them wrong, but their average was nearly perfect. The crowd mean came within a pound of truth.
He published the results in Nature under the title "Vox Populi" and opened with a remarkably modern observation: "This result is, I think, more creditable to the trustworthiness of a democratic judgment than might have been expected."
What happened here was simply that the individual errors canceled out. Some people guessed too high, others too low, but--crucially--their mistakes pointed in different directions. When you aggregate many independent estimates, the noise washes away and what remains is signal.
This was 1907, decades before modern machine learning. Galton had no concept of GPU clusters, so he was left with simple averaging--and yet, it was already unreasonably effective.
Why Averaging Works
The mechanics behind this are actually quite elegant and they generalize perfectly from Galton's fairgoers to ensembles of ML models. Think of each predictor (a person guessing an ox's weight or an XGBoost model predicting returns) as producing an estimate plus an error term. When you average many predictors, the average error shrinks because the idiosyncratic parts cancel out, while any common-mode mistakes remain.
We can write this down precisely under a standard simplifying assumption: N models whose errors all have the same variance σ², and whose average pairwise error correlation is ρ (a rough but useful summary of 'how clone-like' the models are). For an equal-weight average, the ensemble error variance is:
Var(ensemble error) = ρσ² + (1 − ρ)σ² / N
As N grows, the (1 − ρ)σ² / N term vanishes and what remains is ρσ²: the floor set by correlated mistakes. If your models are truly independent (ρ near zero), averaging crushes variance. If they're basically clones (ρ near one), adding more barely helps.
In real-world settings (especially markets), it helps to split error into two buckets: 1) a truly non-reducible floor that no model can beat (irreducible randomness / unmodeled drivers), and 2) a model-dependent component where correlation determines how much averaging helps. Ensembling can only attack the second bucket as whatever everyone is wrong about together will remain.
Let the truly non-reducible part be a constant floor B, normalize so a single model's MSE = 1, and treat ρ as the average correlation of model errors in the remaining (1 − B) part. Then the full equal-weight ensemble MSE is:
MSE(ensemble) = B + (1 − B) · [ ρ + (1 − ρ) / N ]
Here B is 'target noise' (what no model can learn), while ρ controls how correlated the models' mistakes are in the learnable remainder.
The ensemble can never drop below B + (1 − B)ρ, no matter how many models you add. Diversity (low ρ) lowers that floor; more models (large N) just get you to it faster. B is fundamentally irreducible and ρ captures the part of model error that's shared across the crowd.
Experiments with Ensembles
The theory is clean, but the best way to develop intuition is to actually watch it happen. I took the full MSE (lower is better) formula from above, set an illustrative non-cancelable floor of B = 0.20, and swept N from 1 to 50 models across three "diversity regimes:" low, medium, and high. When ρ is low, models are making different mistakes. When ρ is high, they're basically copies of each other:
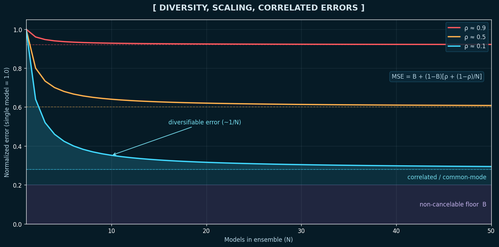
Full MSE for three diversity regimes, normalized so a single model scores 1.0. Assumes equal error variance across models and an illustrative non-cancelable floor (B = 0.20). For the diverse ensemble (ρ ≈ 0.1, cyan), the shading decomposes error into: the non-cancelable floor (B) (bottom), a correlated/common-mode remainder ((1−B)ρ) (middle), and a diversifiable remainder ((1−B)(1−ρ)/N) (top), which shrinks roughly as 1/N. Dashed lines mark each regime's asymptotic floor (B + (1−B)ρ).
The top, coral line explains why "just add more models" so often disappoints in practice. If your models are copycats of the same architecture, same features, and same inductive biases, they have high error correlation and adding more of them barely helps. If all the noise is shared, then there's nothing for the averaging to cancel.
But if your models actually see the problem differently, each new model brings new information and pushes the error floor lower.
Diversity is what makes ensembling work and we now see this is a mathematical fact. In a crowdsourced setting where models come from entirely different people with different backgrounds and different ideas, you get diversity almost for free.
Galton's fairgoers worked precisely because they had different heuristics and different vantage points on the same ox. The farmer who estimated based on bone structure was making different errors than the butcher who estimated based on fat distribution and since those mistakes were uncorrelated, the average was excellent.
CrowdCent: Galton's Ox at Market Scale
The CrowdCent Challenge is an open data science competition where participants build ML models to predict crypto asset returns across all perpetual derivatives listed on Hyperliquid. We aggregate their predictions into a single meta-model.
The beauty of this setup is that it creates exactly the conditions under which ensembling excels. Each participant brings their own features, their own algorithms, their own intuitions, and more. A quant using momentum factors is making completely different errors than a deep learning researcher using embeddings. A mean-reversion model can be negatively correlated with a trend-following model.
The crowd naturally produces the diversity that makes ensembling work and the formula tells us precisely how valuable that diversity is.
Here is what it actually looks like in production. This is real out-of-sample data, 260 consecutive days of live meta-model performance on the Hyperliquid Ranking Challenge, from June 2025 through the beginning of March 2026:
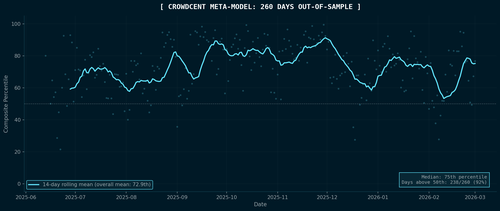
Each dot is a day. The cyan line is a 14-day rolling mean.
The meta-model sits at the 73rd percentile on average. It beats most individual models most of the time, simply by being consistently above median across 260 days of live, non-stationary crypto markets. It sits above the 50th percentile on 92% of all days.
It occasionally has bad days, like in early February 2026 when there was a brief patch where the meta-model dipped below 50th percentile. A regime change occurred, some models broke, and the crowd got temporarily correlated in the same wrong direction. When everyone is wrong together, the ensemble is wrong too. There is no magic that saves you from correlated errors.
But then it recovered and the diversity of approaches reasserts itself as markets settle into new patterns. Temporary drawdowns will sometimes occur when errors align, but are usually followed by recovery as diverse signals reassert themselves.
More participants means more perspectives and the meta-model gets stronger as the crowd grows, but only if that growth adds diversity rather than more of the same.
In noisy, non-stationary markets, model alpha decays and no single model wins forever. The best model this month is often mediocre next month. But the meta-model is robust to individual decay because when one model's edge dies, the ensemble barely notices. The crowd absorbs the loss and keeps moving forward.
The meta-model signal is operationalized through cc-liquid, which can convert the ranking predictions into live portfolio positions on Hyperliquid.
Remember that everything above rests on a single lever of diversity, promoting uncorrelated predictions and orthogonal insight so that errors cancel and the ensemble floor stays low. This is the 1907 insight, and it gets you remarkably far. But there is a second lever.
Incentives and Signaling: The 21st Century Boost
Galton didn't know anything about his participants, so every guess counted the same, and it worked remarkably well. But equal weighting is really the special case where you have zero information about your predictors beyond their predictions themselves. The moment you know anything else about them, you are sitting on additional information that equal weighting likely discards.
The side knowledge could be a track record (this model has been accurate recently). It could be a stake (this model has skin in the game). It could be domain expertise, model confidence, or uniqueness relative to the rest of the crowd. These are all signals about the likely quality of a given prediction, additional information that can be attached to each voice in the crowd to tilt the weights and improve the ensemble.
At CrowdCent, we currently cement this with our CC Points system. Models earn points based on historical out-of-sample accuracy, weighted by an exponential moving average that emphasizes recent performance. The meta-model then weights each participant's predictions in proportion to their EMA accumulated points. Models that have demonstrated consistent predictive skill get a louder voice. Models that have struggled contribute less. But every participant still contributes, preserving the diversity benefits of the full crowd.
To test whether this actually helps, I ran a head-to-head comparison across all 241 scored periods of the Hyperliquid Ranking challenge, from June 2025 through February 2026. For each period, I rebuilt the meta-model twice: once with equal weights (pure Galton-style) and once with points weights (the production scheme). Then I scored both against actual realized crypto returns using Spearman rank correlation.
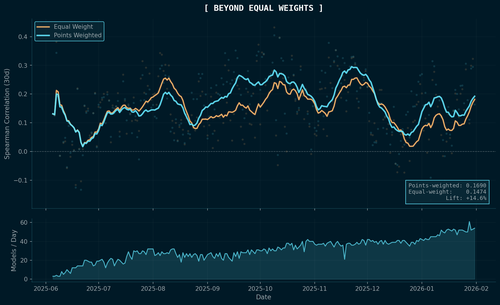
14-day rolling Spearman correlation (30-day horizon) for equal-weight vs points-weighted meta-models, computed across all 241 scored periods. The bottom panel shows the growing model count. The two lines start nearly identical in June 2025 when there's almost no track record, then diverge as the points system accumulates history.
The points-weighted meta-model achieves a mean 30-day Spearman of 0.169 versus 0.147 for equal weight, a 14.6% lift.
The pattern in the chart tells you exactly why. In the earliest periods, when there's almost no history, the two strategies are identical because you have no side information and equal weight is all you can do. As the crowd grows and the system accumulates performance data, the points-weighted version steadily pulls ahead.
Equal weighting is a strong default under maximum ignorance, but the moment you attach information to individual predictors (performance, stake, confidence, anything) you have more to work with, and the ensemble can improve. The principle generalizes well beyond our particular points system: if you can measure something about the quality of a signal, you can try to use it.
Practical Notes
If you're building your own ensemble, I've found there is a natural priority ordering. First, make sure every model clears a baseline quality threshold (garbage in, garbage out, and this is always the case). But once you have that baseline, your marginal returns come almost entirely from increasing diversity rather than improving any individual model further. Different features matter more than different hyperparameters and different algorithms matter more than different random seeds. But, different mindsets and different experience matter most of all.
For aggregation, start with the simple mean as it is shockingly hard to beat. Try rank-averaging if your models are on different scales. Only add weighting schemes if they are clearly justified out of sample, and be suspicious of anything that looks too clever. In my experience, sophisticated weighting schemes mostly overfit to the validation period.
Finally, monitor the pairwise correlation between your model errors over time. This is the number that determines your ensemble's error floor, and if it starts creeping upward, you are losing ensemble value regardless of how many models you add.
Conclusion
We've learned about ensembling, how it works, and the math behind it. Whether we see it with an ox and fairgoers in 1907 or with live ML models predicting 180+ digital assets over 260 consecutive trading days, the ensembling of a diverse crowd outperforms the typical individual and often the best one.
Ensembling a crowd of imperfect predictors is one of the highest-ROI moves in applied machine learning. In live markets, it gives you a signal that degrades gracefully rather than catastrophically as individual models come and go.
That is the thesis behind CrowdCent; the two levers are 1) diversity to lower the error floor, and 2) incentives to attach information to every voice in the crowd. A diverse and incentivized crowd will find truth that no individual can.
Further Reading
- Galton, F. (1907). "Vox Populi." Nature, 75, 450-451.
- Surowiecki, J. (2004). The Wisdom of Crowds. Anchor Books.
- CrowdCent Challenge -- build models, contribute to the meta-model
- cc-liquid -- open-source meta-model portfolio rebalancer
Written in the spirit of The Unreasonable Effectiveness of Recurrent Neural Networks - Andrej Karpathy